Cada primavera se repite la misma escena: más planes de entrenamiento, más descargas de aplicaciones y más ciclistas dispuestos a registrar cada salida, cada pulso y cada cambio de ritmo. Pero detrás de esa rutina ya habitual en el deporte conectado hay una capa menos visible que empieza a ganar peso justo cuando el interés por ponerse en forma vuelve a dispararse. No tiene que ver con vatios, series ni zonas de frecuencia cardíaca, sino con la información que esas plataformas almacenan, cruzan y reutilizan mientras prometen una experiencia cada vez más personalizada.
Más personalización, más datos y más preguntas para los usuarios
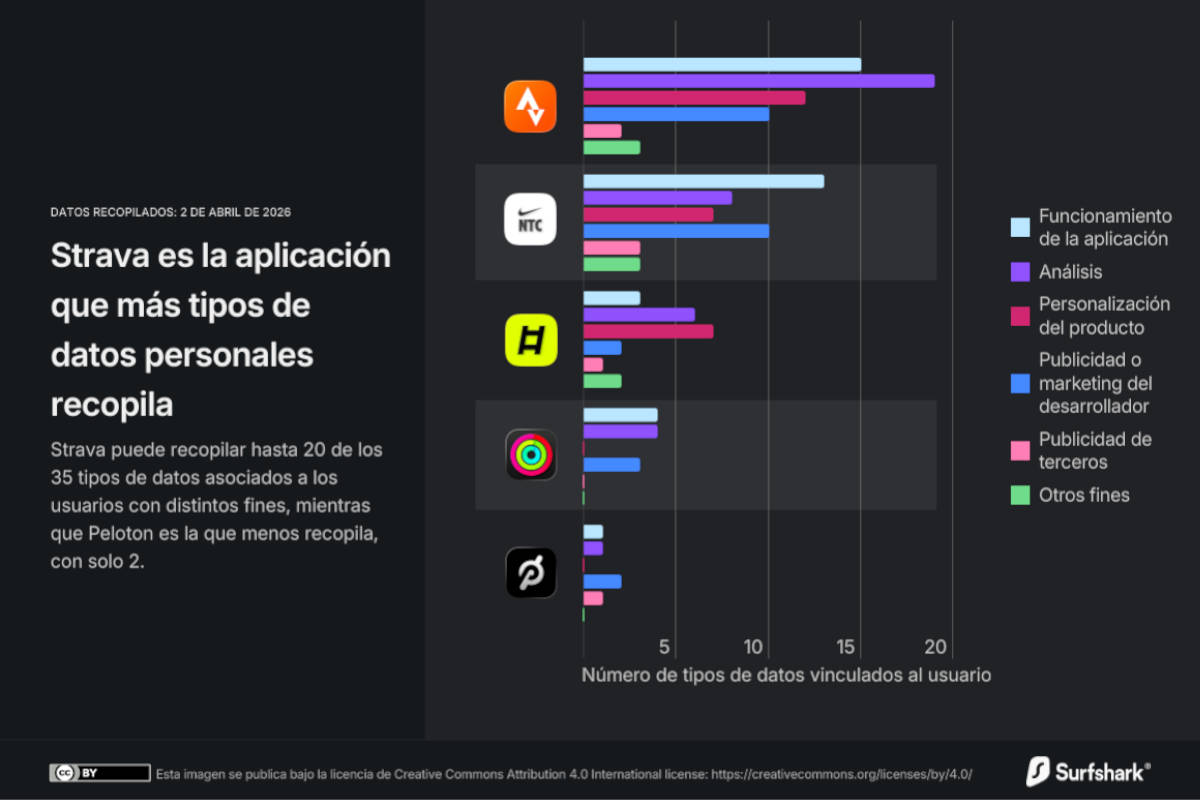
Un estudio publicado por Surfshark sitúa a Strava entre las aplicaciones de entrenamiento con mayor nivel de recopilación de información vinculada a la identidad del usuario. En su análisis, la plataforma deportiva aparece con 20 de los 35 tipos de datos que Apple contempla en las fichas de privacidad de la App Store, por delante de otras apps del sector y muy lejos de servicios como Peloton, que en ese mismo informe figura con solo 2 tipos de datos asociados.
Ese dato coincide además con un momento de fuerte tirón del fitness digital. Surfshark señala que las búsquedas globales relacionadas con "fitness" suelen tocar techo en enero y registran una segunda subida en abril. En la serie analizada desde 2022, enero de 2026 marcó el punto máximo de interés relativo, y el repunte medio de abril ronda el 13 %, una señal clara de que el mercado vuelve a activarse cuando se acerca el verano.
En el caso de Strava, la cuestión no se limita a cuánto recopila, sino a para qué lo usa. La política de privacidad de la compañía, actualizada el 1 de enero de 2026, indica que emplea información para crear, desarrollar, entrenar, probar, mejorar y mantener modelos de inteligencia artificial y aprendizaje automático, propios o de proveedores de servicios. La empresa añade que utiliza datos agregados y desidentificados siempre que es posible en sus funciones de IA.
Ahí aparece uno de los puntos que más afectan al usuario de ciclismo conectado. Strava no es solo un diario de actividades: también concentra datos de ubicación en aplicaciones deportivas, historiales de búsqueda, compras, fotos, vídeos y otros contenidos que ayudan a construir un perfil muy preciso del deportista. En una app centrada en rutas, segmentos y hábitos de entrenamiento, ese volumen de información tiene un valor evidente para personalizar la experiencia, pero también para alimentar sistemas automatizados.
Luis Costa, responsable de investigación en Surfshark, advierte de que el problema no pasa tanto por la llegada de la IA al fitness como por la falta de transparencia real sobre el uso de los datos. Su planteamiento es claro: cuando el usuario activa funciones inteligentes sin comprender qué información cede ni cómo se procesa, la frontera entre mejora del servicio y pérdida de control sobre la privacidad se vuelve mucho más difusa.
Para los ciclistas que usan la app a diario, la lectura práctica es sencilla. Una plataforma como Strava puede saber dónde se entrena, a qué horas se sale, qué recorridos se repiten, qué dispositivos se usan y cómo evoluciona el rendimiento con el paso de las semanas. Esa combinación encaja de lleno en el debate sobre privacidad en plataformas de entrenamiento, sobre todo cuando la información deja de servir solo para registrar actividades y pasa a intervenir en el desarrollo de nuevas funciones algorítmicas.
El informe también pone el foco en el seguimiento publicitario. Cuatro de las cinco aplicaciones analizadas utilizan datos para "tracking", según la información declarada por los desarrolladores en la App Store, mientras que Apple Fitness+ aparece como la única excepción dentro de esa muestra. Ese seguimiento implica vincular información del usuario o del dispositivo con datos obtenidos en otras apps, webs o fuentes externas, algo especialmente sensible cuando se habla de salud, actividad física y hábitos personales.
En un ecosistema cada vez más apoyado en relojes deportivos, ciclocomputadores y wearables, el alcance puede ir incluso más allá. Surfshark recuerda que, cuando estas aplicaciones se conectan a servicios de terceros o a dispositivos externos, pueden entrar en juego datos biométricos adicionales. En el ciclismo, eso significa que métricas que hasta hace poco se entendían como puramente deportivas ya forman parte del terreno de juego de la inteligencia artificial en apps de fitness.
Strava, por su parte, mantiene controles de privacidad para algunos usos agregados de la información. Su documentación de ayuda, actualizada el 26 de marzo de 2026, explica que el ajuste de uso de datos agregados permite decidir si las actividades contribuyen a funciones comunitarias como Strava Metro, el mapa global de calor o los puntos de interés. Ese control no resuelve por sí solo todo el debate sobre IA, pero sí muestra que la compañía distingue entre varias capas de reutilización de datos dentro de su ecosistema.
Aquí el detalle relevante para los usuarios no pasa por abandonar de golpe estas plataformas, sino por entender mejor qué entregan a cambio de la comodidad. El auge del entrenamiento personalizado con IA tiene ventajas claras: recomendaciones más ajustadas, análisis más finos y herramientas más útiles para ordenar la carga de trabajo. El problema aparece cuando esa mejora llega acompañada de políticas extensas, consentimientos poco visibles y una trazabilidad difícil de interpretar para la mayoría de deportistas.